
What does digitally anonymised mean: an explainer
Introduction: why ‘what does digitally anonymised mean’ matters
Understanding what ‘digitally anonymised’ means is important for anyone who shares, receives or analyses data. Digital disguising of contributors and records is increasingly used in journalism, healthcare and research to protect identities while enabling information to be published or examined. For example, at the start of the Lucy Letby programme, Netflix said that ‘some contributors have been digitally disguised to maintain anonymity’, illustrating how digital techniques are applied in public media to reduce exposure of individuals.
Main body: definitions, methods and limits
What is data anonymization?
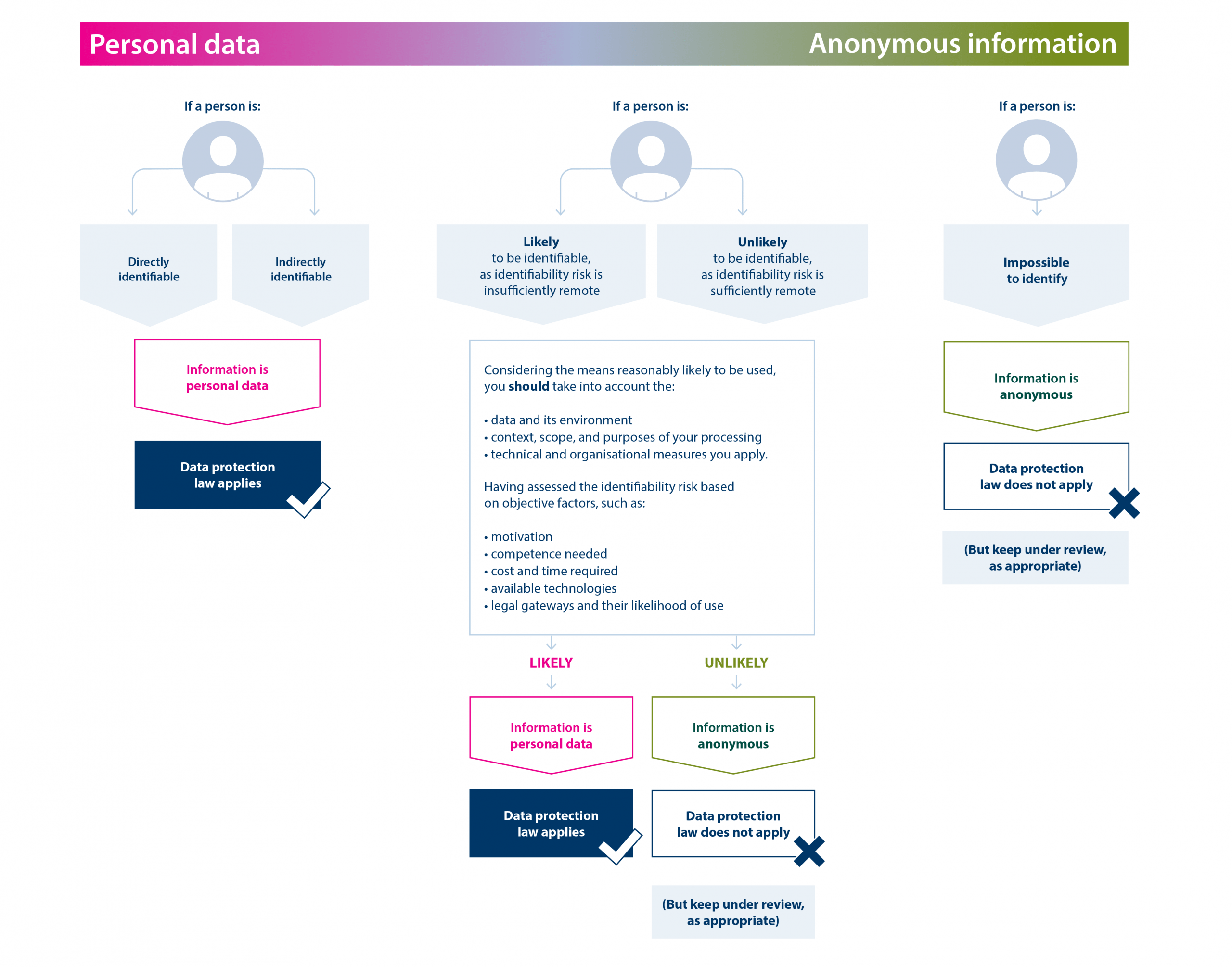
Data anonymization is the process of removing personally identifiable information from data sets so that the people whom the data describe remain anonymous. It has been defined as a ‘process by which personal data is altered in such a way that a data subject can no longer be identified directly or indirectly, either by the data controller alone or in collaboration with any other party.’ Anonymization can make it possible to share information across organisational boundaries while reducing the risk of unintended disclosure and enabling analysis after anonymization.
Pseudonymised versus anonymised data
Pseudonymisation means processing personal data so it can no longer be attributed to a specific person without additional information. Examples include encoding personal data or replacing names with false names. Pseudonymised data may still be considered personal data, and in that case data protection legislation must be complied with during processing.
By contrast, anonymisation refers to processing personal data in a manner that makes it impossible to identify individuals from them. Anonymised data are no longer considered to constitute personal data and so are not subject to data protection regulations.
Limits and risks: de‑anonymization
De‑anonymization is the reverse process in which anonymous data are cross‑referenced with other data sources to re‑identify individuals. Simply deleting names and obvious identifiers will not always render data anonymous because individuals can be identified by other data points in a file. Critics note that in many practical cases you ‘can’t really anonymize your data’ completely, especially where rich datasets can be linked.
Conclusion: implications for readers
In practice, ‘digitally anonymised’ covers a range of techniques from visual disguising in media to technical anonymization and pseudonymisation in data handling. The choice between pseudonymisation and annihilation depends on the use case: whether further analysis is required and what legal safeguards apply. Readers and organisations should be aware that anonymisation reduces but does not always eliminate re‑identification risk, so careful method selection and risk assessment remain essential.